[IT 용어 설명] 파이프라인, TFX(TensorFlow Extended), Kubeflow, Apache Beam, Dataflow, Airflow, CsvExampleGen, Presto, BigQuery ,PrestoExampleGen, BigQueryExampleGen, GCP Dataflow, Configuration First, YAML, backward/forward compatibility, Bazel, Jax, Envoy
안녕하세요 머킹입니다.
위에 제목이 너무 길어서 놀라셨나요..ㅎ
그만큼 알아간 게 많습니다..
오늘은 당근 테크 블로그를 읽었습니다!
평소에 궁금했던 파이프라인에 대해서 읽었습니다 ㅎㅎ
▼ 오늘 읽은 블로그 ▼
TFX와 함께 머신러닝 파이프라인 개발하기
당근마켓에서는 머신러닝 모델을 효과적으로 적용하기 위한 방법에 대해서도 노력하고 있어요. 특히 ML 파이프라인은 주기적인 배포, 빠른 실험, 지속적인 모델 개선을 위해 필수가 되는 경우가
medium.com
파이프라인
머신러닝 모델을 만들고 프로덕트로 배포하는 것은 비교적 쉽습니다.
하지만 파이프라인이 필요한 이유는, 지속적으로 시스템을 유지하며 품질 관리를 하고,
모델의 성능을 개선해 나가는 방향성을 얻기가 어렵기 때문입니다.
일반적인 소프트웨어에서는 추상화가 쉽습니다.
예를 들어, 몬스터라는 클래스가 있으면, 슬라임 오크 같은 몬스터는 HP, MP 등의 속성이 있고
이런 속성들이 체계적으로 있기 때문입니다.
하지만 머신러닝에서는 모델을 추상화하기 어렵습니다.
그렇기 때문에, 모델을 부분적으로 개선하는 게 어렵고,
뭘 넣으면 뭐가 나온다라고 딱 정하기 어려워 Unit 테스트를 진행하는 것도 어렵습니다.
이런 문제들을 해결하는 게 머신러닝 파이프라인의 핵심입니다.
[Machine Learning] 머신러닝 파이프라인의 이해 (MLOps) <인프런 - 머신러닝 엔지니어 실무>
안녕하세요 이번 포스팅에선 MLOps의 핵심 문제와 이를 이해하기 위한 배경을 알아보겠습니다. 인프런의 "머신러닝 엔지니어 실무" 강의의 첫 번째 맛보기 영상을 보고, 공부하며 정리한 내용입
bio-info.tistory.com
파이프라인이 이런 뜻이었군요!
출처 블로그에 되게 잘 설명이 되어 있어서 한 번에 이해했습니다.
확실히.. 파이프라인 설계가 정말 정말 정말 중요하다고 생각이 되네요.
TFX(TensorFlow Extended)
Tensorflow를 십분 활용하여 데이터 가공부터 학습, 검증까지 일련의 과정을 파이프라인으로 제공하는 프레임워크예요.
그뿐만 아니라 모델을 실제 프로덕션에 서빙하기 전 실 서버와 같은 환경에서 트래픽을 보내보고 검증하거나, 모델 서빙에 필요한 Warmup 데이터가 포함된 모델로 생성하고 서빙까지 모든 과정을 지원해요.

위 그림을 보면 TFX의 개략적인 흐름을 파악할 수 있어요.
파이프라인이기 때문에 모든 과정을 각각의 컴포넌트로 구성할 수 있고, 개별적으로도 분리해서 사용할 수도 있답니다.
출처 : https://tech.scatterlab.co.kr/use-tfx-pipeline-with-customization/ (스캐터랩 기술 블로그)
구글 기술 블로그에도 있어서 이 블로그도 참고하면 좋을 것 같습니다.
https://developers-kr.googleblog.com/2019/11/tensorflow.what-exactly-is-this-tfx-thing.html
프로덕션 환경에서 실제로 사용되는 머신러닝, TensorFlow Extended(TFX)에 대해 소개합니다
게시자: Robert Crowe , Konstantinos (Gus) Katsiapis , Kevin Haas (TFX 팀을 대표해 게시함) 사람들은 머신러닝에 대해 생각할 때, 보통은 지금 만들 수 있는 훌륭한 모델에 대해서만 생각합니...
developers-kr.googleblog.com
십분 활용했다는 표현이 정말 맞는 표현이네요 ㅎㅎ
Kubeflow
Kubeflow는 Kubernetes + ML flow를 합한 의미로, 파이프라인이라는 ML워크플로를 구축하고 배포하기 위해 제공되는 플랫폼입니다.
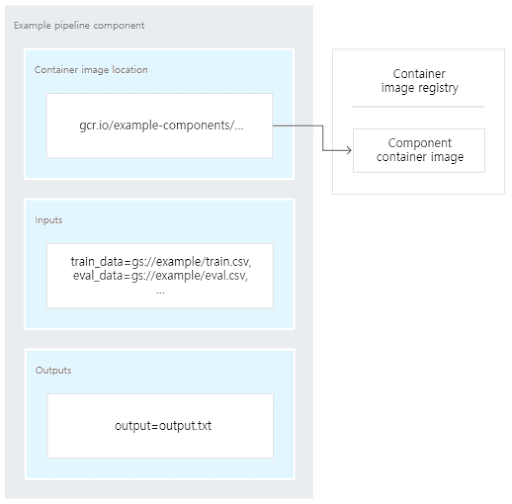
AI HUB의 파이프라인 워크플로우는 데이터 사전 처리, 데이터 변환, 모델 학습 등과 같은 단계로 구성되어 있습니다. 워크플로우의 구성요소는 입력 매개 변수 세트, 출력 세트 및 컨테이너 이미지의 위치로 구성되어 있습니다. 구성요소의 컨테이너 이미지는 구성 요소의 실행 코드와 코드가 실행되는 환경의 정의를 포함하는 패키지로 이루어져 있습니다.
Kubeflow 시작하기
Kubeflow는 Kubernetes + ML flow를 합한 의미로, 파이프라인이라는 ML워크플로를 구축하고 배포하기 위해 제공되는 플랫폼입니다. 개발, 테스트 및 프로덕션 수준 서비스를 위해 다양한 환경에 ML 시스
www.bespinglobal.com
출처 블로그에 되게 상세하게 설명이 되어 있었습니다.
쿠버네티스와 ML flow를 합한 의미였군요.
저는 왠지 특정 툴이나 도구 등이 이름만 보고 끌리는 경우가 있는데
그중 하나가 쿠버네티스였습니다.
그래서 굉장히 열심히 배워보고 싶은 것 중 하나입니다 ㅎㅎ
Apache Beam
Apache Beam은 일괄 및 스트리밍 파이프라인을 모두 정의할 수 있는 오픈소스 통합 모델입니다.
Apache Beam 프로그래밍 모델을 사용하면 대규모 데이터 처리 방식이 간단해집니다.
Apache Beam SDK 중 하나를 사용하여 파이프라인을 정의하는 프로그램을 빌드합니다.
출처 : https://cloud.google.com/dataflow/docs/concepts/beam-programming-model?hl=ko
Apache Beam 프로그래밍 모델 | Cloud Dataflow | Google Cloud
의견 보내기 Apache Beam 프로그래밍 모델 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. Dataflow는 오픈소스 Apache Beam 프로젝트를 기반으로 합니다. 이 문서에
cloud.google.com
출처인 구글에 굉장히 잘 나와있네요!
유튜브 영상도 있으니까 궁금하신 분들은 보시면 좋겠습니다.
Dataflow
Data Flow (데이터 플로우) 데이터 플로우는 다양한 데이터 소스로부터 대용량의 데이터를 추출하고,
스트림/배치 데이터의 변환/전송에 대한 처리 흐름을 시각적으로 작성하는 데이터 처리 흐름 도구로,
오픈소스 Apache NiFi를 제공합니다.
출처 : https://www.samsungsds.com/kr/analyltics-data-flow/data-flow.html
Data Flow | 클라우드 상품 | 삼성SDS - 빅데이터 통합 플랫폼, 데이터 플로우
삼성SDS의 Data Flow(데이터 플로우)는 다양한 데이터 소스로부터 대용량의 데이터를 추출하고, 스트림/배치 데이터의 변환/전송에 대한 처리 흐름을 시각적으로 작성하는 데이터 처리 흐름 도구로
www.samsungsds.com
되게 이런 기술 관련 용어들을 찾다 보면 제가 잘 모르는 분야를 알게 돼서 신기해요.
특히 이런 상품이 있구나.. 싶어서 되게 발전한 산업을 훌쩍 느낀답니다.
Airflow
airflow는 airbnb에서 만든 workflow를 만드는 오픈소스 프로젝트입니다.
python 코드로 워크플로우(workflow)를 작성하고, 스케쥴링, 모니터링하는 플랫폼입니다.
스케쥴링을 하고 모니터링을 코드로 작성하기 때문에 더 세분화할 수 있으므로,
더 정교화된 파이프라인을 구성할 수 있습니다.
예약된 워크플로를 트리거하고 실행할 실행기에 Task을 제출하는 두 가지를 모두 처리하는 스케줄러입니다.
출처 : https://magpienote.tistory.com/192
이렇게 이름의 유래를 알게 되면 유명 기업들이나 본인의 이름들을 따는 경우를 종종 보는데
신기하면서도 귀엽다고 생각합니다 ㅎㅎ
CsvExampleGen
ExampleGen은 SchemaGen, StatisticsGen 및 Example Validator와 같은 TensorFlow 데이터 검증 라이브러리를
사용하는 구성 요소에 데이터를 제공합니다.
또한, TensorFlow Transform 라이브러리를 사용하는 Transform에 데이터를 제공하고
궁극적으로 추론 중에 배포 대상에 데이터를 제공합니다.
출처 : https://www.tensorflow.org/tfx/guide/examplegen?hl=ko
PrestoExampleGen, BigQueryExampleGen
PrestoExampleGen과 BigQueryExampleGen은 TensorFlow Extended (TFX)의 구성 요소 중에서 데이터를 추출하고 전처리하는 역할을 하는 두 가지 ExampleGen 구현체입니다.
- PrestoExampleGen:
- PrestoExampleGen은 TFX의 ExampleGen 구성 요소 중 하나로, Presto 데이터베이스에서 데이터를 추출하는 데 사용됩니다.
- Presto는 분산형 쿼리 엔진으로, 다양한 데이터 소스에서 데이터를 쿼리 할 수 있습니다. PrestoExampleGen은 Presto를 사용하여 데이터를 가져와서 TFX 워크플로우에서 사용할 수 있는 Example 프로토콜 버퍼 형식으로 변환합니다.
- BigQueryExampleGen:
- BigQueryExampleGen은 TFX의 또 다른 ExampleGen 구성 요소로, Google의 BigQuery 데이터베이스에서 데이터를 추출하는 데 사용됩니다.
- BigQuery는 대규모의 정형화된 데이터를 처리하기 위한 서비스로, 대용량 데이터셋을 쿼리하고 처리할 수 있습니다. BigQueryExampleGen은 BigQuery를 통해 데이터를 가져와서 TFX 워크플로우에서 활용할 수 있는 Example 프로토콜 버퍼 형식으로 변환합니다.
이 두 ExampleGen은 TFX 워크플로우의 일부로 사용되며, 워크플로우의 다른 구성 요소와 함께 데이터 추출 및 전처리 단계를 자동화하는 데 기여합니다.
Presto
Presto란?
Presto는 Facebook 개발자가 대량의 데이터에 대해 대화형 분석을 실행하기 위해 만든 오픈소스 분산 SQL 쿼리 엔진입니다. Presto를 사용하는 조직은 새로운 복잡한 언어를 학습하지 않고도 기존 SQL 기술을 사용하여 빅데이터를 쿼리할 수 있습니다.
오픈소스 Presto(SQL 쿼리 엔진)는 업계 표준 SQL 쿼리 언어를 사용하여 온프레미스 시스템과 클라우드에서 여러 소스의 빅데이터를 빠르고 쉽게 처리하고 임시 분석을 수행할 수 있는 방법을 제공합니다.
되게 똑똑한 엔진이네요..
저도 나중에 꼭 써보고 싶습니다.
된다면 어떤 구조로 이뤄졌길래 다양한 쿼리를 사용할 수 있는 건지 보고 싶네요!
BigQuery
빅쿼리(Big Query)는 머신러닝, 지리정보 분석, 비즈니스 인텔리전스와 같은 기본 제공 기능을 이용해 데이터를 관리하고 분석할 수 있게 해주는 데이터 웨어하우스입니다.
구글 빅쿼리(Big Query)란? - 파인데이터랩 - 티스토리
데이터 웨어하우스
데이터 웨어하우스는 데이터 분석을 위해 특별히 설계되었으며,
여기에는 대량의 데이터를 읽어 데이터 전반에 걸친 관계와 추세를 파악하는 작업이 포함됩니다.
Apache Beam
Apache Beam은 일괄 및 스트리밍 파이프라인을 모두 정의할 수 있는 오픈소스 통합 모델입니다.
Apache Beam 프로그래밍 모델을 사용하면 대규모 데이터 처리 방식이 간단해집니다.
Apache Beam SDK 중 하나를 사용하여 파이프라인을 정의하는 프로그램을 빌드합니다.
병렬처리를 위한 라이브러리라고 생각하면 될 것 같습니다.
GCP Dataflow
Google Cloud Dataflow는 Google Cloud Platform (GCP)에서 제공되는 클라우드 기반의 데이터 처리 서비스입니다. Dataflow는 대규모 데이터 집합을 효율적으로 처리하고 변환하기 위한 스트리밍 (real-time) 및 배치 (batch) 데이터 처리 모델을 지원합니다. 이 서비스는 Apache Beam이라는 오픈 소스 프로젝트를 기반으로 하고 있습니다.
Dataflow를 사용하면 사용자는 데이터 처리 파이프라인을 구축하고 실행할 수 있으며, 이러한 파이프라인은 대용량 데이터를 신속하게 처리하고 원하는 형식으로 변환할 수 있습니다. Dataflow는 다양한 데이터 소스 및 대상과 통합되어 있으며, 특히 Apache Beam SDK를 사용하여 다양한 언어에서 파이프라인을 작성할 수 있습니다.
Dataflow의 주요 특징과 장점은 다음과 같습니다:
- 유연한 데이터 처리 모델: Dataflow는 배치 및 스트리밍 데이터 처리를 지원하므로 실시간 및 일괄 처리를 통합하여 다양한 요구 사항에 대응할 수 있습니다.
- 자동 확장 및 최적화: Dataflow는 클라우드 환경에서 자동으로 확장되며, 작업에 필요한 리소스를 동적으로 할당하여 처리량을 최적화합니다.
- 서버리스 아키텍처: 사용자는 인프라 관리에 신경 쓰지 않고 데이터 처리에 집중할 수 있습니다. Dataflow는 서버리스 아키텍처를 기반으로 하며, Google Cloud에서 관리되는 서비스로 제공됩니다.
- 풍부한 플랫폼 통합: 다양한 데이터 소스와 대상, 그리고 GCP의 기타 서비스들과의 강력한 통합을 제공합니다.
Dataflow는 대규모 데이터 처리 및 변환 작업을 간소화하고 개발자가 더 적은 관리 노력으로 데이터 파이프라인을 구축하고 실행할 수 있도록 지원하는 강력한 도구입니다.
Configuration First
"Configuration First"는 소프트웨어 개발 또는 시스템 설계 접근 방식 중 하나를 나타냅니다.
이 접근 방식은 구성(Configuration)에 중점을 두고 개발하는 방법론을 의미합니다.
즉, 소프트웨어나 시스템을 설계할 때 설정(configuration)을 우선적으로 고려하고
이를 중심으로 개발을 진행하는 방법을 말합니다.
"Configuration"은 일반적으로 어떤 시스템이나 소프트웨어의 동작을 결정하는 속성, 설정, 환경 변수 등을 가리킵니다. "Configuration First" 접근 방식은 이러한 설정을 명확하게 정의하고 관리함으로써
시스템의 유연성, 확장성, 유지 보수성을 개선하려는 목적을 가지고 있습니다.
이 방법론을 따르는 경우, 개발자는 다음과 같은 원칙을 따를 수 있습니다:
- 설정 파일 우선: 시스템이나 애플리케이션의 동작을 제어하는 중요한 설정은 별도의 설정 파일에 명시적으로 정의됩니다.
- 환경 변수 활용: 환경 변수를 통해 설정을 동적으로 제어하고, 여러 환경에서의 배포를 용이하게 합니다.
- 외부 구성 서비스 활용: 외부의 구성 서비스를 활용하여 동적인 구성 정보를 관리할 수 있습니다.
- 디폴트 값 정의: 모든 설정에는 기본값이 있어야 하며, 설정이 없는 경우에는 이러한 기본값을 사용함으로써 시스템의 안정성을 유지합니다.
이러한 "Configuration First"의 접근 방식은 특히 클라우드 기반 서비스, 마이크로서비스 아키텍처,
컨테이너화된 애플리케이션 등 현대적인 개발 환경에서 유용하게 적용될 수 있습니다.
설정을 명시적으로 다루는 것은 유지보수성을 향상하고, 환경 간 이식성을 높이는 데 도움이 됩니다.
YAML
YAML은 구성 파일 작성에 자주 사용되는 데이터 직렬화 언어입니다.
YAML은 사람이 읽을 수 있기 때문에 프로그래밍 언어 중에서도 인기가 높습니다.
1. YAML이란?
YAML은 사람이 읽기 쉽게 만들어진 데이터 직렬화 양식이며, 처음에는 Yet Another Markup Language라는 의미로 사용되다가 현재는 YAML Ain't Markup Language라는 재귀적 의미로 바꾸어 YAML은 마크업이 아니라 데이터가 중심이라고 말하고 있습니다.
YAML은 C, Perl, XML, Python 등 다양한 프로그래밍 언어에서 유래한 기능을 가지고 있으며, 특히 Python 스타일의 들여 쓰기 방법으로 중첩을 표시하기 때문에 Python 개발자는 더욱 친숙하게 느껴질 수 있습니다.
앞서 이야기했듯이 YAML은 사람이 읽기 쉽게 만들어졌는데, 이는 괄호 문자를 사용하지 않고, 키-값(Key: Value) 형태로 작성되기 때문이라고 필자는 생각하고 있습니다.(하지만 YAML에서도 중괄호와 대괄호를 사용하기도 하며, 이는 사용하지 않을 수 있습니다. 이에 대한 내용은 이 글의 뒤에서 다룹니다.) 그래서 필자는 JSON 보다 YAML을 더 선호하는 편입니다. 아래는 JSON 포맷과 YAML 포맷을 비교한 그림입니다.

backward/forward compatibility
- Backward Compatibility (하위 호환성):
- 뜻: 새로운 버전이나 업데이트가 이전 버전과 호환되는 능력을 나타냅니다. 즉, 새로운 변경 사항이나 기능이 추가된 경우에도 기존 버전에서 동작하도록 보장합니다.
- 예시: 사용자가 어플리케이션을 업그레이드했을 때, 이전에 작성된 코드나 데이터와의 호환성을 유지하면 해당 어플리케이션이 하위 호환성을 가진 것입니다.
- Forward Compatibility (상위 호환성):
- 뜻: 현재 버전에서 개발된 소프트웨어나 시스템이 향후 버전에서 동작할 수 있는 능력을 나타냅니다. 즉, 미래에 발생할 변경 사항에 대비하여 현재 버전이나 설계가 그에 대응할 수 있도록 하는 것을 의미합니다.
- 예시: 새로운 데이터 필드를 추가했을 때, 현재 시스템이 이를 인식하고 처리할 수 있도록 설계되어 있다면 해당 시스템은 상위 호환성을 가진 것입니다.
하위 호환성과 상위 호환성은 각각 역방향과 순방향 호환성으로도 불립니다.
이러한 호환성은 소프트웨어나 시스템이 변화하는 환경에서 유지보수성과 확장성을 보장하는 데 중요한 역할을 합니다.
Bazel
Bazel은 Google에서 개발한 오픈 소스 빌드 도구로, 소프트웨어 프로젝트를 빌드하고 테스트하는 데 사용됩니다.
Bazel은 확장성, 성능, 다양한 언어 지원, 재현성, 확장 가능한 빌드 규칙 등의 특징을 갖춘 강력한 빌드 시스템입니다.
여러 언어로 작성된 소스 코드를 지원하며, Java, C++, Python, Go, JavaScript 등 다양한 언어에 대한 빌드를 지원합니다. Bazel은 모듈화 된 빌드 규칙을 사용하며, 각 모듈은 독립적으로 빌드되어 캐시에 저장되므로 중복 빌드를 방지하고 빠른 빌드를 제공합니다.
Bazel의 주요 특징은 다음과 같습니다:
- 다양한 언어 지원: Bazel은 다양한 언어에 대한 빌드를 지원하며, 여러 언어를 하나의 프로젝트에서 혼합하여 사용할 수 있습니다.
- 확장 가능한 빌드 규칙: 사용자 정의 빌드 규칙을 작성하여 프로젝트에 특화된 빌드 프로세스를 정의할 수 있습니다.
- 캐시를 통한 빠른 빌드: 이전에 빌드한 결과물을 캐시에 저장하여 중복된 빌드를 방지하고 빠른 빌드를 제공합니다.
- 클라우드 환경 지원: Bazel은 클라우드 환경에서도 효과적으로 동작하도록 설계되어 있어 대규모 분산 빌드에 적합합니다.
- 재현성: 동일한 소스 코드에서 항상 동일한 빌드 결과를 보장하므로 빌드의 재현성이 확보됩니다.
- 테스트 및 빌드 통합: Bazel은 테스트와 빌드가 강력하게 통합되어 있어 변경 사항에 대한 빠른 피드백을 제공합니다.
Google 내부에서 사용되었던 Blaze라는 빌드 시스템을 기반으로 하여 개발되었으며, 오픈 소스로 공개되어 개발자들이 다양한 프로젝트에 적용할 수 있도록 되어 있습니다.
Jax
JAX는 고성능 수치 계산을 위한 오픈 소스 라이브러리로, 특히 행렬 및 텐서 연산을 효율적으로 수행할 수 있는
라이브러리입니다. JAX는 주로 머신 러닝 및 과학적 계산을 위한 확장 가능하고 유연한 라이브러리로 사용됩니다.
JAX의 주요 특징과 개념은 다음과 같습니다:
- 자동 미분 (Automatic Differentiation): JAX는 자동 미분을 지원하여 복잡한 수학적 연산의 도함수를 자동으로 계산할 수 있습니다. 이는 머신 러닝 모델의 학습 및 최적화에 중요한 역할을 합니다.
- NumPy 호환성: JAX는 NumPy와 유사한 API를 제공하며, NumPy 코드를 거의 수정하지 않고 JAX로 이전할 수 있도록 하는 것이 목표 중 하나입니다. 이는 기존의 NumPy 코드를 쉽게 JAX로 이식할 수 있게 해 주어 기존 코드의 재사용성을 높입니다.
- XLA 컴파일러 (Accelerated Linear Algebra Compiler): JAX는 XLA를 사용하여 효율적인 컴파일된 코드를 생성합니다. 이는 CPU와 GPU를 비롯한 다양한 하드웨어에서 고성능을 제공하며, 특히 대규모 머신 러닝 모델의 학습에 적합합니다.
- Functional Programming 및 Composable Transformations: JAX는 함수형 프로그래밍 스타일을 채택하고 변환 가능한(Composable) 변환을 제공하여 여러 변환을 조합하여 복잡한 계산을 구성할 수 있습니다.
- Device 병렬성 및 분산 컴퓨팅 지원: JAX는 다양한 하드웨어에서의 병렬 및 분산 컴퓨팅을 지원하여 대규모 데이터와 모델에 대한 계산을 효율적으로 처리할 수 있습니다.
JAX는 Google Research에서 개발되었으며, TensorFlow와의 관련성도 있습니다. TensorFlow와 함께 사용할 수 있고, 특히 TensorFlow Probability 및 Trax와 같은 라이브러리에서도 JAX가 활용되고 있습니다.
구글은... 정말 많이 개발하는군요..?
Envoy
Envoy는 현대적인 분산 시스템에서 사용되는 오픈 소스 프록시 및 로드 밸런서입니다. Lyft에서 개발되었으며, 많은 기업과 프로젝트에서 활발하게 사용되고 있습니다. Envoy는 마이크로서비스 아키텍처 및 서비스 메시 패턴에서 네트워크 트래픽을 관리하고 보안, 모니터링, 라우팅, 재시도 등 다양한 기능을 제공합니다.
Envoy의 주요 특징과 기능은 다음과 같습니다:
- 프록시 및 로드 밸런싱: Envoy는 클라이언트와 서버 간의 트래픽을 중개하고 로드 밸런싱을 수행하여 서비스에 대한 안정성과 성능을 향상시킵니다.
- 서비스 디스커버리: Envoy는 서비스 디스커버리 메커니즘과 통합되어, 동적으로 서비스의 상태를 감지하고 트래픽을 서비스 인스턴스로 분산시킵니다.
- HTTP/2 및 gRPC 지원: Envoy는 현대적인 웹 서비스에서 널리 사용되는 프로토콜인 HTTP/2와 gRPC를 지원합니다.
- 보안 기능: Envoy는 TLS/SSL을 통한 암호화, 인증, 권한 부여와 같은 보안 기능을 제공합니다.
- 트래픽 모니터링: Envoy는 Prometheus, StatsD 등과 통합되어 트래픽 및 성능 데이터를 수집하고 모니터링할 수 있습니다.
- 설정 및 확장성: Envoy의 구성은 JSON을 사용하며, 동적으로 변경이 가능하므로 런타임에 수정할 수 있습니다. 또한 필터와 플러그인을 통해 쉽게 확장 가능합니다.
- 클라우드 네이티브 환경: Kubernetes 및 Istio와 같은 클라우드 네이티브 환경에서 사용할 수 있도록 설계되어 있습니다.
Envoy는 CNCF(Cloud Native Computing Foundation)의 쿠벤테스 프로젝트 중 하나로 인정받고 있으며, 서비스 메시 아키텍처에서 중요한 역할을 하는 도구 중 하나로 간주됩니다.
이 설명이 너무 어려워서 추가적인 설명을 부탁했습니다.
- 로드 밸런서 (Load Balancer):
- 뜻: 로드 밸런서는 네트워크나 애플리케이션 트래픽을 여러 서버 또는 서비스 인스턴스로 분산시켜서 부하를 분산하고 성능을 향상시키는 장치나 시스템을 말합니다. 클라이언트 요청을 받아 여러 서버에 분배함으로써 각 서버의 부하를 조절하고, 가용성과 안정성을 높일 수 있습니다.
- 인스턴스로 분산 (Distributed to Instances):
- 뜻: 이 문구는 로드 밸런서가 클라이언트 요청을 여러 서버 인스턴스로 분산시킨다는 것을 나타냅니다. 로드 밸런서는 트래픽을 서버 인스턴스들 사이에 고르게 분배하여 각 서버가 비슷한 부하를 갖도록 합니다.
- gRPC:
- 뜻: gRPC는 Google에서 개발한 오픈 소스 RPC (Remote Procedure Call) 프레임워크로, 다양한 언어 간에 분산된 시스템에서 효율적인 통신을 제공합니다. Protocol Buffers를 기반으로 하며, HTTP/2를 사용하여 효율적인 통신과 다양한 기능을 제공합니다.
- TLS (Transport Layer Security)와 SSL (Secure Sockets Layer):
- TLS와 SSL 뜻: TLS와 SSL은 암호화 및 보안 통신을 위한 프로토콜입니다. SSL은 초기 버전이었으며, 보안 취약점이 발견되어 TLS가 개발되었습니다. 일반적으로 두 용어는 보안 소켓 통신을 지칭하는 데에 사용됩니다.
- Prometheus와 StatsD:
- Prometheus 뜻: Prometheus는 오픈 소스 시스템 및 응용 프로그램 모니터링 및 경고 도구입니다. Metric 데이터를 수집하고 저장하며, 강력한 쿼리 언어를 제공하여 실시간 모니터링을 할 수 있습니다.
- StatsD 뜻: StatsD는 애플리케이션의 통계를 수집하고, 간단한 형태의 메트릭 데이터를 전송하는 네트워크 데몬입니다. 주로 애플리케이션 성능 모니터링을 위해 사용됩니다.
'AI' 카테고리의 다른 글
| [용어설명] IT 테크 블로그 용어 설명집 (0) | 2023.12.07 |
|---|---|
| [용어설명] IT 테크 블로그 용어 설명집 (0) | 2023.11.30 |
| [용어설명]FMOps,LangChain,프롬프트 체이닝,토큰 소비량,전이 학습,엔드 투 엔드 플랫폼,코파일럿,Agile (0) | 2023.11.17 |
| [Suno-ai] AI로 간단하게 노래 만들기 (0) | 2023.10.24 |
| 더 간단한 Stable Diffusion 사용하기 (프롬프트) (0) | 2023.10.20 |


