[IT 용어 설명] 멀티 스텝 추론(Multi-Step Reasoning), 할루시네이션(Hallucination),'Reasoning', 'Evidence Selector', 'Factually Consistent Generation'
안녕하세요 머킹입니다.
오늘 읽은 블로그는!
네이버에서 공개한 Cue에 대한 기술 블로그입니다
▼ 오늘 읽은 블로그 ▼
https://channeltech.naver.com/contentDetail/64
Cue: 샅샅이 파헤쳐보기
서비스 방향부터 개발 비하인드까지
channeltech.naver.com
Cue의 탄생을 이렇게 보니까 얼마나 고생하셨을지..
감히 말할 수 없을 정도로 노력한 부분들이 글에 나타났습니다.
그리고 IT용어를 잘 몰라도
쉽게 이해할 수 있는 단어들로 이루어져 있어서
굉장히 수월하게 읽었어요.
멀티 스텝 추론(Multi-Step Reasoning),
Multi-step reasoning은 여러 단계로 이뤄진 추론 또는 논리적 추론을 의미합니다.
이는 일련의 정보나 조건들을 고려하여 복잡한 문제나 질문에 대한 해답을 찾아내는 과정을 말합니다.
이러한 추론은 여러 개의 중간 단계를 거치며,
각 단계에서는 이전 단계의 결과나 중간 정보를 활용하여 최종 결론에 도달하는 방식입니다.
예를 들어, 어떤 문제에 대한 해답을 찾기 위해 여러 조건들을 고려하고, 이를 바탕으로 중간 단계의 결론을 도출하며,
이러한 중간 결론들을 종합하여 최종적인 해답을 얻어내는 과정이 Multi-step reasoning의 예가 될 수 있습니다.
이러한 추론과정은 인간이 일상생활에서 다양한 상황에서 문제를 해결하거나 논리적으로 생각하는 과정과 유사하며,
인공 지능과 머신러닝 분야에서는 이러한 능력을 모델이 가지도록 학습시키는 것이 중요한 주제 중 하나입니다.
할루시네이션(Hallucination)
할루시네이션(hallucination)은 본래 '환각(幻覺)'을 뜻하는 정신의학 용어로,
인공지능 영역에서는 AI가 잘못된 정보를 생성하는 현상 또는 기술적 오류를 말합니다.
인공지능(AI)이 주어진 데이터나 맥락에 근거하지 않은 잘못된 정보나 허위 정보를 생성하는 것을 의미한다.
환각이나 환청을 뜻하는 정신의학 용어에서 단어를 빌려왔다.
업계는 AI가 처음부터 잘못된 데이터로 학습하는 것을 원인으로 보고 있다.
AI 언어 모델은 데이터를 학습해 확률상 가장 높은 대답을 내놓지 진위는 확인할 수 없기에 얼핏 그럴듯해 보이지만 말도 안 되는 답을 내는 오류를 범한다는 것이다.
만약 인간이 악의적으로 오염된 데이터를 학습시킬 경우 위험해질 수 있기에 최근 주요 7개국(G7) 정부는 ‘챗GPT’ 등 AI 모델을 사용할 때 책임을 부여해야 한다는 취지의 공동성명을 채택하기도 했다.
출처 : https://www.sedaily.com/NewsView/29QQ49U8UC
'Reasoning', 'Evidence Selector', 'Factually Consistent Generation'
- Reasoning (추론):
- AI에서 "Reasoning"은 모델이 주어진 입력 데이터나 정보를 기반으로 논리적으로 판단하고 결론을 도출하는 능력을 의미합니다. 이는 모델이 데이터 간의 관계를 이해하고 새로운 정보에 대한 추론을 수행하는 데 관련됩니다.
- Evidence Selector (증거 선택자):
- "Evidence Selector"는 모델이 주어진 정보 또는 데이터 중에서 특정한 부분을 선택하고 강조하는 기능을 나타냅니다. 이는 모델이 특정 주장이나 결론을 지지하기 위해 적절한 증거를 선택하거나 가중치를 부여하는 과정을 의미합니다.
- Factually Consistent Generation (사실적 일관성 유지 생성):
- "Factually Consistent Generation"은 AI 모델이 새로운 텍스트를 생성할 때 주어진 사실에 모순되지 않고 일관성 있게 내용을 형성하는 능력을 나타냅니다. 모델은 생성된 텍스트가 주어진 문맥과 사실에 부합하도록 유의하며 작업을 수행합니다.
Cue의 시작이 시애틀이라는 것도 놀라웠어요.
그리고 모든 시작이 그렇듯 처음에는 마음에 들고 이걸 왜 써?라는 여론이지만
점차 데이터는 늘어갈 테니 네이버가 가는 방향이 틀리지 않았다고 생각합니다.
국내 최대 포털이라는 장점이 어마무시한 기업이니까요!
오늘은 글이 짧아서 아쉬우니까
Cue가 사용하는 검색 모델에 대해서 조금만 더 알아보겠습니다.
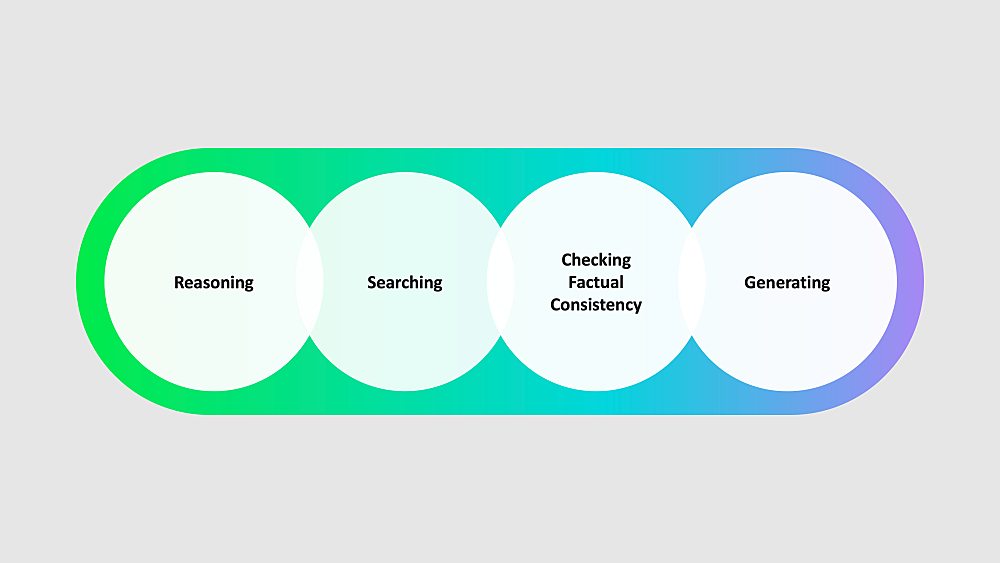
Cue:는 추론, 검색, 사실적 일관성의 확인, 그리고 답변을 생성합니다. 여기서 가장 주목해야 될 부분은 검색입니다.
이것은 Cue:가 학습 데이터에 의존하는 것이 아니라, 검색 결과에 grounding 된 답변을 생성한다는 것을 의미합니다.
그래서 우리는 Cue:를 검색 목적 달성을 돕는 어드바이저라고 정의합니다.
출처 : https://channeltech.naver.com/contentDetail/46
Cue: 생성형 AI 기반 차세대 검색 서비스
김용범 | 최재호 NAVER
channeltech.naver.com
이렇듯 Cue는 목적 달성을 돕는 어드바이저입니다.
즉 사용자가 만약 여행을 가고 싶다면 ㅇㅇ 맛집, ㅇㅇ 비행기, ㅇㅇ 날씨.. 등 굉장히 고려해야 할 부분들이 많죠.
그런 불편함을 하나로 압축해서 'xx.xx.xx부터 xx까지 ㅇㅇ 여행 계획해 줘'라는 문장으로요.
생성 AI의 특징과 단점
생성 AI 모델의 특징과 단점은 다양하며, 모델의 종류에 따라 차이가 있을 수 있습니다.
그러나 일반적으로 생성 AI의 특징과 단점은 다음과 같습니다.
특징:
- 창의성과 다양성:
- 생성 AI는 새로운 아이디어나 콘텐츠를 생성하는 데 높은 창의성을 보일 수 있습니다. 이는 예측할 수 없는 결과물을 만들어낼 수 있음을 의미합니다.
- 자동화된 작업 수행:
- 생성 AI는 자동화된 작업을 수행할 수 있어, 텍스트 생성, 이미지 생성, 음성 생성 등 다양한 분야에서 유용하게 활용될 수 있습니다.
- 학습 데이터 기반의 개선:
- 대규모 학습 데이터를 기반으로 하여, 모델은 다양한 맥락에서 일관된 결과를 생성할 수 있습니다.
단점:
- 일관성과 편향:
- 생성 AI는 학습 데이터에 내재된 편향을 반영할 수 있고, 일관성이 부족할 때가 있습니다. 모델이 부정확한 정보를 생성할 수도 있습니다.
- 사용자의 의도 파악 어려움:
- 모델이 사용자의 의도를 정확하게 이해하기 어려울 수 있어, 부적절한 결과물을 생성할 우려가 있습니다.
- 데이터 기반의 공격에 취약:
- 생성 AI는 대량의 데이터를 기반으로 작동하므로, 악의적인 의도로 조작된 데이터에 민감할 수 있습니다. 이로 인해 모델의 결과물이 왜곡될 수 있습니다.
- 연산 비용과 환경 부담:
- 일부 생성 AI 모델은 대규모 연산을 필요로 하며, 이는 컴퓨팅 리소스와 전력 소비 등에 부담을 줄 수 있습니다.
- 윤리적 고려사항:
- 생성 AI의 결과물이 윤리적인 문제를 일으킬 수 있으며, 그에 대한 책임 소재에 대한 논의가 이뤄지고 있습니다.
네이버가 앞으로 나아갈 방향에서 많은 고착이 없길 바라며
이 글을 마칩니다!
'AI' 카테고리의 다른 글
| [용어정리] 딥러닝 기본 개념 정리 (0) | 2024.01.10 |
|---|---|
| [용어설명] IT 테크 블로그 용어 설명집 (0) | 2023.12.07 |
| [용어설명] IT 테크 블로그 용어 설명집 (0) | 2023.11.21 |
| [용어설명]FMOps,LangChain,프롬프트 체이닝,토큰 소비량,전이 학습,엔드 투 엔드 플랫폼,코파일럿,Agile (0) | 2023.11.17 |
| [Suno-ai] AI로 간단하게 노래 만들기 (0) | 2023.10.24 |


