[자연어 용어정리] 언어 모델, 셀프 어텐션, GPT, 벡터
언어 모델(language model)
단어 시퀀스에 확률을 부여하는 모델입니다.
다시 말해 시퀀스를 입력 받아 해당 시퀀스가 얼마나 그럴듯한지 확률을 출력하는 모델입니다.
이전 단어를이 주어졌을 때 다음 단어가 나타날 확률을 부여하는 모델
순방향 언어 모델

문장 앞부터 뒤로, 사람이 이해하는 순서대로 계산하는 모델을
순방향 언어 모델이라고 합니다.
GPT, ELMo 모델이 이런 방식으로 프리트레인을 수행합니다.
역방향 언어 모델
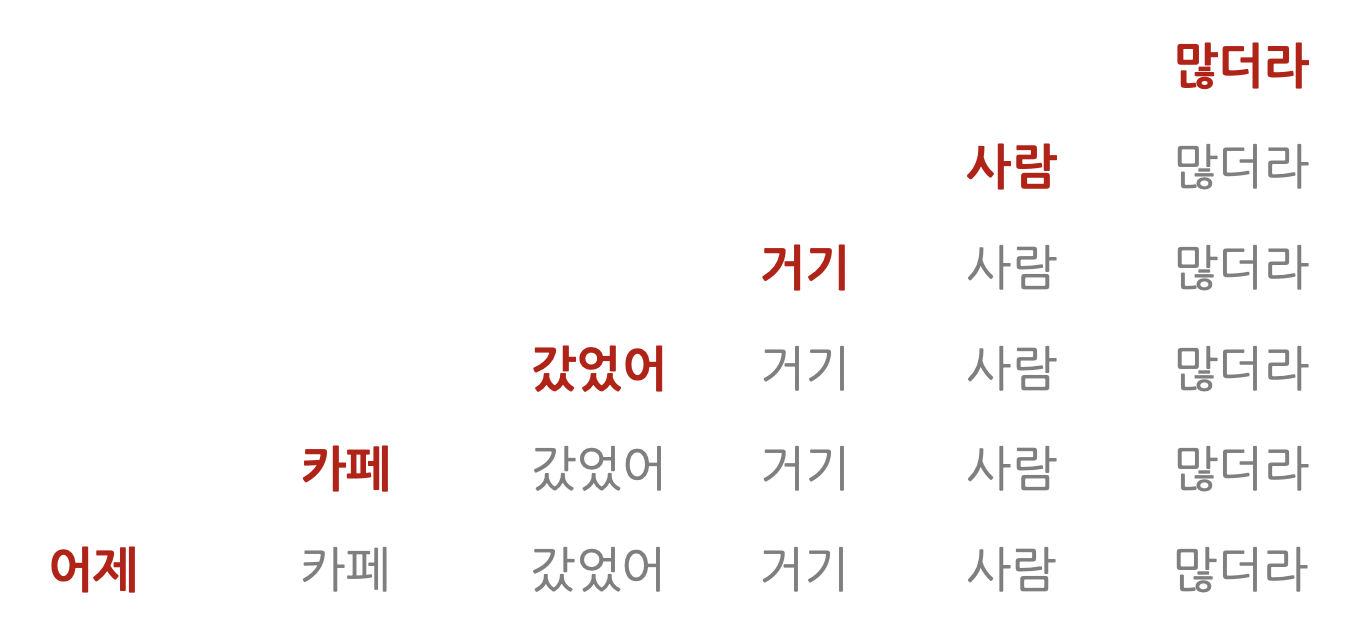
문장 뒤부터 앞으로 계산하는 모델입니다.
ELMo 같은 모델이 이런 방식으로 프리트레인을 수행합니다. ( ELMo 모델은 순방향, 역방향을 모두 활용합니다)
마스크 언어 모델
학습 대상 문장에 빈칸을 만들어 놓고 해당 빈칸에 올 단어로 적절한 단어가 무엇일지 분류하는 과정으로 학습합니다.
BERT 가 대표적인 마스크 언어 모델입니다.
맟힐 단어를 계산할 때 문장 전체의 맥락을 참고할 수 있다는 장점이 있습니다.
스킵-그램 모델
어떤 단어 앞뒤에 특정 범위를 정해 두고 이 범위 내에 어떤 단어들이 올지 분류하는 과정으로 학습합니다.
컨텍스트로 설정한 단어 주변에 어떤 단어들이 분포해 있는지 학습합니다.
**언어 모델이 주목받는 이유 가운데 하나는 데이터 제작 비용 때문입니다.
'다음 단어 맞히기'나 '빈칸 맞히기' 등으로 학습 태스크를 구성하면 사람이 일일이 수작업해야 하는
레이블 없이도 많은 학습 데이터를 싼값에 만들어 낼 수 있습니다.**
시퀀스-투-시퀀스
시퀀스란 단어 같은 무언가의 나열을 의미합니다.
특정 속성을 지닌 시퀀스를 다른 속성의 시퀀스로 변환하는 작업을 가리킵니다.
소스와 타깃의 길이가 달라도 해당과제를 수행하는 데 문제가 없어야 합니다.
인코더와 디코더
인코더는 소스 시퀀스의 정보를 압축해 디코더로 보내는 역할을 담당합니다.
인코더가 소스 시퀀스 정보를 압축하는 과정을 인코딩이라고 합니다.
디코더는 인코더가 보내준 소스 시퀀스 정보를 받아서 타깃 시퀀스를 생성합니다.
디코더가 타깃 시퀀스를 생성하는 과정을 디코딩이라고 합니다.
트랜스포머
디코더 출력은 타깃 언어의 어휘 수 만큼의 차원으로 구성된 벡터입니다.
이 벡터의 특징은 요소(element)값이 모두 확률이라는 점입니다.
타깃 언어의 어휘가 총 3만 개라고 가정하면 디코더 출력은 3만 차원의 벡터입니다.
트랜스포머는 인코더와 디코더 입력이 주어졌을 때
정답에 해당하는 단어의 확률값을 높이는 방식으로 학습합니다.
어텐션(Attention)
시퀀스 요소 가운데 중요한 요소에 집중하고 그렇지 않은 요소는 무시해
태스크 수행 성능을 끌어 올리는 방식입니다.
셀프어텐션이란, 입력 시퀀스 가운데 태스크 수행에 의미 있는 요소들 위주로 정보를 추출합니다.
말 그대로 자신에게 수행하는 어텐션 기법입니다.
셀프 어텐션 수행 대상은 입력 시퀀스 전체입니다.
어텐션은 소스 시퀀스 전체 단어들 사이를 연결하는 데 쓰입니다.
반면 셀프 어텐션은 입력 시퀀스 전체 단어들 사이를 연결합니다.
셀프 어텐션은 RNN 없이 동작합니다.
타깃 언어의 단어를 1개 생성할 때 어텐션은 1회 수행하지만
셀프 어텐션은 인코더, 디코더 블록의 개수만큼 반복 수행합니다.
셀프 어텐션은 쿼리, 키, 밸류 3가지 요소가 서로 영향을 주고받는 구조입니다.
쿼리와 키를 행렬곱한 뒤 해당 행렬의 모든 요솟값을 키 차원 수의 제곱근으로 나누고,
이 행렬을 행 단위로 소프트맥스를 취해 스코어 행렬로 만들어 줍니다.
이 스코어 행렬에 밸류를 행렬곱하면 셀프 어텐션 계산을 마칩니다.
소프트맥스란 입력 벡터의 모든 요솟값 범위를 0~1로 하고 총합이 1이 되게끔 하는 함수입니다.
멀티 헤드 어텐션(Multi-Head Attention)
셀프 어텐션을 동시에 여러 번 수행하는 걸 가리킵니다.
여러 헤드가 독자적으로 셀프 어텐션을 계산하는 것 입니다.
멀티 헤드 어텐션의 최종 수행 결과는 '입력 단어 수 X 목표 차원 수' 입니다.
멀티 헤드 어텐션은 인코더, 디코더 블록 모두 적용됩니다.
마스크 멀티 헤드 어텐션(Masked Multi-Head Attention)
정답을 포함한 타깃 시퀀스의 미래 정보를 셀프 어텐션 계산에서 제외(마스킹)하게 됩니다.
타킷 시퀀스에 대한 마스크 멀티 헤드 어텐션 계산 시 제외 대상 단어들의 소프트맥스 확률이 0이 되도록 하여
멀티 헤드 어텐션에서도 해당 단어 정보들이 무시되게 하는 방식으로 수행됩니다.
피드포워드 뉴럴 네트워크(Feedforward neural network)
신경망의 한 종류로 입력층, 은닉층, 출력층으로 구성되어 있습니다.
트랜스포머에서 사용하는 피드포워드 뉴럴 네트워크의 활성 함수는 ReLU입니다.
잔차 연결(residual connection)
블록이나 레이어 계산을 건너뛰는 경로를 하나 두는 것을 말합니다.
블록 계산이 계속될 때 잔차 연결을 두는 것은 효과가 있습니다.
모델이 다양한 관점에서 블록 계산을 수행하게 됩니다.
딥러닝은 레이어가 많아지면 학습이 어렵습니다 (모델을 업데이트하기 위한 신호가 전달되는 경로가 길어지기 때문에)
잔차 연결은 모델 중간에 블록을 건너뛰는 경로를 설정함으로써 학습을 쉽게 하는 효과까지 거둘 수 있습니다.
레이어 정규화(layer normalization)
미니 배치의 인스턴스별로 평균을 빼주고 표준편차로 나눠 정규화를 수행하는 기법입니다.
레이어 정규화를 수행하면 학습이 안정되고 그 속도가 빨라지는 등의 효과가 있습니다.
드롭아웃(Dropout)
과적합 현상을 방지하고자 뉴런의 일부를 확률적으로 0 으로 대치하여 계산에서 제외하는 기법입니다.
트랜스포머 모델에서 드롭아웃은 입력 임베딩과 최초 블록 사이, 블록과 블록 사이,
마지막 블록과 출력층 사이에 적용합니다.
아담 옵티마이저(Adam optimization)
딥러닝 모델 학습은 모델 출력과 정답 사이의 오차를 최소화 하는 방향을 구하고
이 방향에 맞춰 모델 전체의 파라미터들을 업데이트 하는 과정입니다.
이때 오차를 손실, 오차를 최소화하는 방향을 gradinet라고 합니다.
그리고 오차를 최소화 하는 과정을 최적화(optimization)이라고 합니다.
파라미터란 행렬, 벡터, 스칼라 따위의 모델 구성 요소입니다.
오차를 구하려면 현재 시점에서의 모델의 입력을 넣어서 처음부터 끝까지 계산해보고 정답과 비교해야 합니다.
이처럼 오차를 구하려고 모델 처음부터 끝까지 계산하는 것을 순전파(forward propagation)라고 합니다.
오차를 구했다면 오차를 최소화 하는 최초의 gradinet를 구할 수 있습니다.
미분으로 구할 수 있는데 이후 미분의 연쇄법칙에 따라 모델 파라미터별 gradinet를 구할 수 있습니다.
이를 역전파라고 합니다(back propagation)
모델 파라미터를 업데이트 할 때 최적화 도구의 도움을 받습니다.
트랜스포머는 아담을 사용합니다.
아담은 방향과 보폭을 적절하게 정해줍니다.
'AI' 카테고리의 다른 글
| [용어정리] 문서 분류 모델, 감성 분석 (0) | 2024.02.06 |
|---|---|
| [용어정리]GPT와 BERT 비교 (0) | 2024.02.04 |
| [용어정리] 토큰화, 어휘, BEP (0) | 2024.01.31 |
| [용어정리] 자연어 처리 (0) | 2024.01.29 |
| [용어 정리]모델 경량화, ViT, Transformer, GPT, BERT (0) | 2024.01.26 |
